K-Means with their feature selection in RapidMiner
4 min readAug 31, 2021
Related Research
Design

Without Feature Selection
- accuracy: 65.52%

- split data: 0.01, accuracy: 66.22%

Unsupervised Feature Selection with k-means
- balance of simplicity: 1.0 = accuracy: 63.23%

- balance of simplicity: 0.5 = accuracy: 63.23%

- split data: 0.01, balance of simplicity: 1.0 = accuracy: 57.72%

- split data: 0.01, balance of simplicity: 0.5 = accuracy: 66.22%

Try to use different feature selection model
K-Means (H2O)

- notsplit 0.5

- notsplit 1.0

- split 0.5

- split 1.0

X-Means

- notsplit 0.5

- notsplit 1.0

- split 0.5

- split 1.0

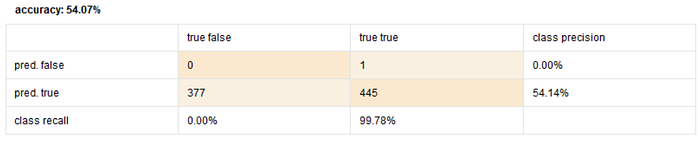
K-NN
- split max 20

- split max 30

Naive Bayes
- split max 20

- split max 30

Decission Tree
- split max 20
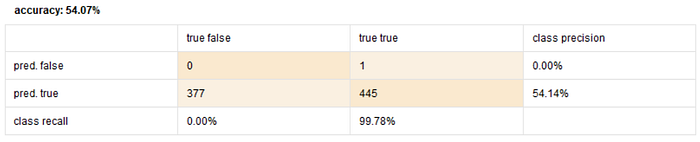
- split max 30